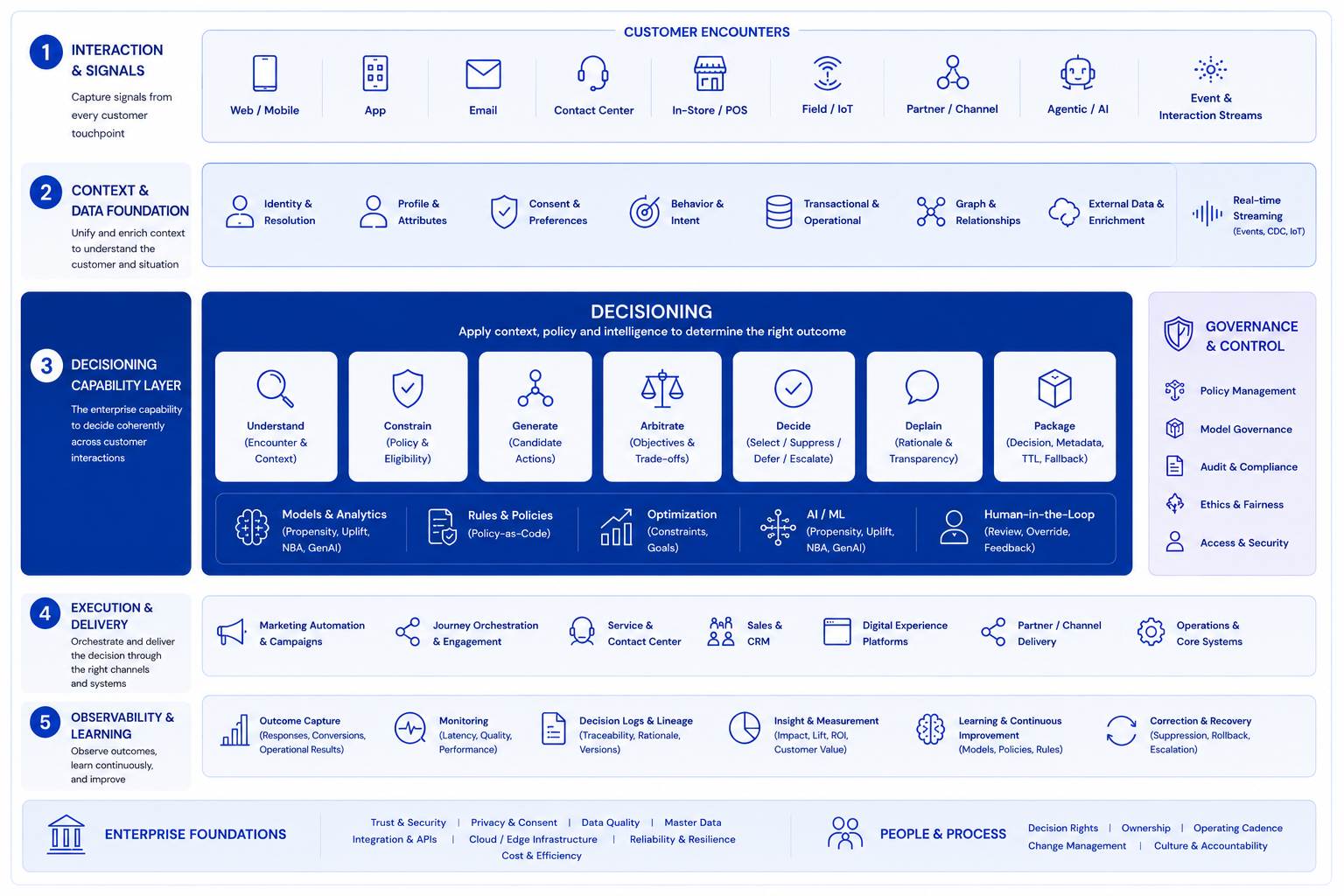
“Context graph” is becoming one of those terms that shows up everywhere just before the industry decides what it actually means.
That alone is not a reason to dismiss it. Some of the most useful ideas in enterprise technology arrive in an unstable state. They begin as half-formed language around a real problem. People reach for the term because something important is missing, even if they cannot yet describe it cleanly.
That is where context graphs seem to be landing.
The strongest version of the idea is not especially mysterious. Traditional systems of record are good at capturing current state: the customer, the account, the ticket, the quote, the case, the object. What they tend to lose is the decision reality around that state. The exceptions. The approvals. The precedent. The override. The weird edge case that got resolved in Slack, on a call, or by someone who simply “knew how this usually gets handled.” Foundation Capital’s recent thesis sharpens that well: the missing layer is not just data, but decision traces — the “why” behind what happened. Their claim is that as those traces accumulate across entities and time, they form a context graph: a queryable map of how the organization actually makes decisions.
That is a serious idea.
It is also one that can get overstated very quickly.
Because as soon as the term “context graph” enters the AI conversation, it starts attracting multiple ambitions at once. Enterprise memory. Agent grounding. Process understanding. Decision lineage. Operational intelligence. Context engineering. Explainability. Governance. All of those are real needs. None of them are identical.
That is why this concept deserves more discipline than hype.
The problem it names is real
Start with what is strongest.
There is clearly a missing layer between systems of record and effective AI or human decision support. Glean frames the problem in operational terms: AI models may use tools, but they still lack the process knowledge needed to understand how work actually gets done. Their definition of a context graph connects enterprise entities — people, documents, tickets, systems — with temporal traces of actions and events so AI can understand not just what exists, but how work flows in practice.
That is directionally right.
Neo4j pushes the same idea from a graph perspective: current-state systems tell you what is true now, but not enough of the institutional knowledge, relationships, or reasoning history needed for reliable enterprise-grade decisions.
In other words, the context-graph concept is not trying to solve a fake problem. It is responding to a real gap:
- State without lineage,
- Records without precedent,
- Workflows without memory,
- Automation without enough organizational reality around it.
That gap matters more as AI agents move closer to action.
Where the concept starts to blur
The problem is not the problem. The problem is the category.
At the moment, “context graph” is carrying at least three different ideas:
- A graph of enterprise entities and relationships,
- A graph of decision traces and operational memory,
- A broader claim about the context layer needed to make AI work.
Those overlap, but they are not the same thing.
That is why the term still feels early. It has clearly penetrated the discourse. Foundation Capital has helped popularize it. Glean has operationalized its own version of it. Neo4j has given it technical form. Atlan has tried to distinguish it from knowledge graphs by saying knowledge graphs model “what things are,” while context graphs add lineage, temporal context, governance rules, and decision traces to describe “how things work” and “why decisions were made.”
That all sounds coherent at a distance.
Up close, it still leaves important questions open.
How much of this is just a knowledge graph with operational metadata?
How much is really a new category?
How much is a useful design pattern?
How much is venture language around a real but still-forming layer?
My answer is: some of each.
Where I think the current framing is strongest
The strongest use of “context graph” is not as a total enterprise mirror. It is as a decision-memory layer.
That means:
- Exception history,
- Approval history,
- Policy application,
- Lineage of why something happened,
- Searchable precedent,
- Operational memory for agents and humans.
That is credible. Useful. Increasingly feasible.
It is also easier to believe technically than the broader versions of the pitch. A bounded graph of approvals, traces, episodes, handoffs, decisions, and relevant relations is very plausible. Modern graph tooling, event streams, retrieval layers, and agent frameworks make that quite real.
Where the idea becomes weaker is when it starts sounding like a complete answer to “context” more broadly.
Because that is where enterprise software often gets into trouble.
The risk: decision reality starts sounding like customer reality
This is where I think the market needs to be careful.
A context graph may become a very useful representation of organizational decision reality. That does not mean it captures customer reality in any complete sense.
That distinction matters more than it may first appear.
A graph of approvals, exceptions, policies, tickets, documents, people, and workflows can tell an organization a great deal about how it makes decisions. It can even make AI agents better grounded and more explainable. But the moment that gets confused with customer understanding, the claim expands too far.
This is the same pressure that has haunted enterprise customer technology for years. Older labels such as Customer 360 and the single view of the customer already carried the fantasy that customer reality could be progressively assembled into an enterprise asset. Newer language — context engineering, agent context, decisioning layers — can end up refreshing the same claim with better branding. That is exactly the critique raised in The Context Fantasy: the enterprise works with a partial, temporary operational view, not possession of customer context in any complete sense.
This is why context graphs are interesting. It is also why they are dangerous when overstated.
My current view
I would not dismiss context graphs.
I would also not grant them more than they have earned.
The best way to hold the idea right now is this:
Context graphs are a credible emerging pattern for modeling enterprise decision lineage, relational continuity, and AI-operational memory.
They are much less convincing when marketed as if they solve the harder problem of customer context itself.
That is where the conversation gets more serious.
Because once the term stabilizes, we will have to decide what it really names:
- A new graph category,
- A better memory layer for agents,
- A system of decisions,
- Or just the latest umbrella for context engineering.
My instinct is that the answer will be narrower than the hype and more useful than the skepticism.
That is usually how good categories begin.
For Executives
In the full breakdown, I go deeper on:
- Whether context graphs are technically feasible or mostly rhetorical,
- How much they have actually penetrated the industry,
- Where they overlap with knowledge graphs,
- Why I think Encounter Graph is still a stronger concept for Customer Technology,
- And why “customer context” remains the wrong thing to think of as fully graph-ownable.
Read the deep dive here: The Context Confusion, mapped.